搜索到
5
篇与
的结果
-
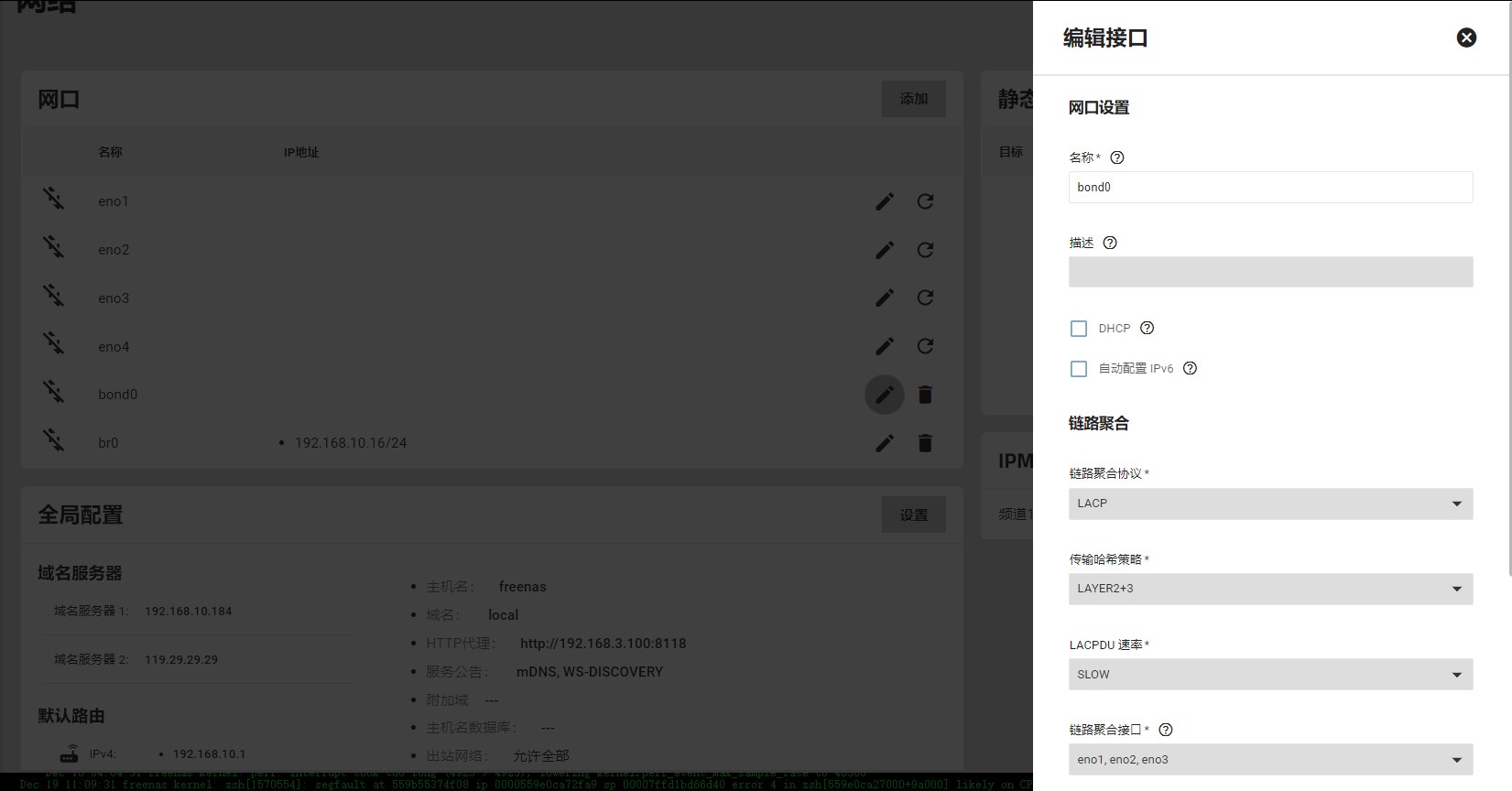
 TrueNAS zfs raidz扩展磁盘expand 背景 在使用 TrueNAS 4年后的今天,终于迎来了存储池空间使用率超过了90%,存储池是使用的 10 块 2T 做的 raidz3,即可以损失任意3块盘仍然保证数据安全,剩余的空间计算为 (10-3) x 2T = 14T,实际最大可用空间 11.98T,而现在剩余可用空间不足 1T 扩容问题 手头上刚好有一块 2T 的磁盘,是否可以加进去直接扩展空间呢? 尝试在池中加入新盘,提示需要添加 5块 硬盘,实在难以理解为何一次扩容需要5块盘,因为之前玩群晖组raid6扩展还是相当方便的,基本上新增一块、两块扩展空间都可以。 所以根据这个特殊的要求,我查阅了一些资料,才发现问题不止是扩展需要5块硬盘那么简单,最少要5块是会在此池中新建一个vdev组,它具有此池相同的raidz功能,所以raidz3最低的要求是5块新盘,但它不会扩展到原有的空间,那这个方案是相当浪费空间的 于是我查询了一些关于raidz、zfs扩展的资料,截至到2024.08.01最新的资料如下: # 12楼 https://www.truenas.com/community/threads/raidz-expansion-best-method-when-increasing-disks-and-replacing-with-larger-at-same-time.105448/ # 4楼 https://www.truenas.com/community/threads/adding-a-drive-to-a-raidz1-pool.111805/ # 正规文档关于之前是如何扩展的(新建一个vdev) https://openzfs.org/wiki/OpenZFS_Developer_Summit_2023_Talks#RAIDZ_Expansion_(Matt_Ahrens_&_Don_Brady) # 关于解决方案和其他的一些讨论 https://www.truenas.com/community/threads/adding-disk-to-raidz1.111375/ # 关于扩展以及扩展后数据分布的讨论 https://github.com/openzfs/zfs/pull/15022 # 关于扩展以及数据分布的讨论后续 https://github.com/openzfs/zfs/discussions/15232 关于上面的讨论,大概在今年底 TrueNAS 可以集成这一功能,但不知道能否解决数据分布问题,raidz 与 raid 完全不同,其扩展后不会重新分布数据,导致原数据与新数据盘符存储不同,推荐的方法是,删除原数据重新创建,则会以新盘的数量重新分布 PS. 其他的解决方案 较推荐的是把原硬盘一个一个更换更大的盘,每更换一个则等到同步完成再继续,等所有硬盘更换后会自动扩展空间 新建一个更大的池,然后把数据同步过去
TrueNAS zfs raidz扩展磁盘expand 背景 在使用 TrueNAS 4年后的今天,终于迎来了存储池空间使用率超过了90%,存储池是使用的 10 块 2T 做的 raidz3,即可以损失任意3块盘仍然保证数据安全,剩余的空间计算为 (10-3) x 2T = 14T,实际最大可用空间 11.98T,而现在剩余可用空间不足 1T 扩容问题 手头上刚好有一块 2T 的磁盘,是否可以加进去直接扩展空间呢? 尝试在池中加入新盘,提示需要添加 5块 硬盘,实在难以理解为何一次扩容需要5块盘,因为之前玩群晖组raid6扩展还是相当方便的,基本上新增一块、两块扩展空间都可以。 所以根据这个特殊的要求,我查阅了一些资料,才发现问题不止是扩展需要5块硬盘那么简单,最少要5块是会在此池中新建一个vdev组,它具有此池相同的raidz功能,所以raidz3最低的要求是5块新盘,但它不会扩展到原有的空间,那这个方案是相当浪费空间的 于是我查询了一些关于raidz、zfs扩展的资料,截至到2024.08.01最新的资料如下: # 12楼 https://www.truenas.com/community/threads/raidz-expansion-best-method-when-increasing-disks-and-replacing-with-larger-at-same-time.105448/ # 4楼 https://www.truenas.com/community/threads/adding-a-drive-to-a-raidz1-pool.111805/ # 正规文档关于之前是如何扩展的(新建一个vdev) https://openzfs.org/wiki/OpenZFS_Developer_Summit_2023_Talks#RAIDZ_Expansion_(Matt_Ahrens_&_Don_Brady) # 关于解决方案和其他的一些讨论 https://www.truenas.com/community/threads/adding-disk-to-raidz1.111375/ # 关于扩展以及扩展后数据分布的讨论 https://github.com/openzfs/zfs/pull/15022 # 关于扩展以及数据分布的讨论后续 https://github.com/openzfs/zfs/discussions/15232 关于上面的讨论,大概在今年底 TrueNAS 可以集成这一功能,但不知道能否解决数据分布问题,raidz 与 raid 完全不同,其扩展后不会重新分布数据,导致原数据与新数据盘符存储不同,推荐的方法是,删除原数据重新创建,则会以新盘的数量重新分布 PS. 其他的解决方案 较推荐的是把原硬盘一个一个更换更大的盘,每更换一个则等到同步完成再继续,等所有硬盘更换后会自动扩展空间 新建一个更大的池,然后把数据同步过去 -
群晖修改raid类型以及无法删除文件 0x1 如何修改raid类型 群晖有一个池是无需数据安全的,以前只做了raid1,现在空间不够用,如果扩展类型发现只能选择镜像盘了,无法对容量进行修改。 我们既然想保持池的数据、池的编号,手头上现在另一块差不多大小的硬盘,可以操作如下: 新建一个池x 停止所有服务,把原池内容拷贝到新池 删除原池 空出来的硬盘新建池,选择 JBOD,这个类型允许多个不同大小的硬盘合并成一个池,以使用所有硬盘的空间,但是它不保证数据安全 再把池x的内容拷贝到JBOD池,删除池x,把空余出来的硬盘扩展到JBOD池 0x2 后续异常 后续可能发生容器无法启动以及无法删除某些文件的情况 在做了上面的迁移后,我这边是重新安装了 docker 套件的,有两个原因,1是想把 docker 套件直接安装到新池内,2是池内迁移其实也涉及到容器的挂载目录,总是需要停止的,所以就索性重新安装了 在重装 docker 到新池后,打开 docker 发现需要迁移并且升级容器,但任务完成后 三个容器有两个容器无法正常启动,docker 日志中显示找不到命令 非常奇怪,删除容器、重启docker套件再次安装仍然无法解决,最后准备删除所有 docker 文件,仅保留 容器 配置文件,但在 原池 的以下目录删除文件时候出现如下错误: root@ootoo:/volume2# rm -rf \@docker/btrfs/ rm: cannot remove '@docker/btrfs/subvolumes/b2dd884d91a67023b19fe756b30395dfba14bf459f021114c412dc9b530f637e': Operation not permitted rm: cannot remove '@docker/btrfs/subvolumes/13da7b8998fc585e55340ee05f50890d9362e003aa78af9ca357aecdcb6739a3': Operation not permitted 这些文件无法使用 rm 删除,因为是 btrfs ,需要使用专用命令删除,示例如下: btrfs subvolume del b2dd884d91a67023b19fe756b30395dfba14bf459f021114c412dc9b530f637e btrfs subvolume del * 删除相关文件后,外层的目录即可正常使用 rm 删除了 再完全删除 docker 安装文件、镜像,重装 docker 套件后,再次使用之前的方式启动容器,使用恢复正常
-
-
truenas core 升级到 scale 0x1 注意事项 升级是官方支持,并且比较容易,但受限点在于 core 是基于 freebds 开发的,是类unix系统,scale 是21年开始的支线,是基于 linux 开发的,所以有些功能是不兼容的,以下是几个注意点: scale 不支持 core 的虚拟机和 jail,因为这两个都是 freebds 的功能,与linux技术不符 然后有一些服务也是在 scale 中拿掉了,因为 scale 支持更广,可以使用其他方式来部署,不需要作为 core 中的服务 如果有 GELI 的池,需要先导出恢复到非加密池中,这样 scale 才能正常使用这个池 还有一些环境变量、其他服务的数据等,以及系统用户创建的规则 core 升级到 scale 对大版本和小版本有一定要求,但范围内都可以 完全升级成功是不可回退,需要备份好数据 0x2 为什么 freebds 是基于 unix 的,一些服务使用起来不方便,并且相对于linux支持的插件、服务更少,jail听说可以实现许多功能,但是学习资料少,学习成本高,所以最终是选择使用linux 0x3 升级步骤 因为之前基本上使用的 nfs 共享,没有使用 虚拟机 或者 jail,所以基本上不需要做很多的这些清理和备份,保留池以及池内关键数据做好备份即可,然后使用下面步骤: 备份好 core 的配置文件 刻录好 scale 的镜像 关闭机器,使用新的系统盘 重启安装 scale,选择安装到新的系统盘 重启后登录到 scale,恢复之前备份的配置文件 在存储中可以看到之前的池被导入,且其他配置恢复 PS. 这里升级有个重要的点可以确定下,就是在没有完全升级成功的情况下,用之前core的系统盘是可以正常启动到之前环境的。也就是说 truenas 升级并不会影响数据盘,除非升级成功之后点击了升级数据池(在后续确认了,如果两个盘分别安装了core和scale,那么可以轮流启动使用都没问题,所以所谓的单向升级、不能回滚仅针对于zfs 池版本升级后,那么不能够再使用core) 0x4 异常和故障 此次升级也并不是一帆风顺的,其中有几个点需要注意下: 使用u盘作为系统盘真的很烂,这估计就是为什么之前高版本freenas以及后面的truenas都不推荐使用个u盘作为系统盘的原因,购买的两个u盘只作为系统盘半年,再次安装scale的时候写入出现io错误,并且写入速度非常慢,整个流程使用了6个小时(正常外置硬盘盒的固态是30-60分钟),正常固态硬盘是十几分钟左右。最后硬盘盒也是不被推荐的,truenas的说法是usb设备都不再推荐。 在升级完成后原本两个数据池,但是只能看到一个SSD的固态池,另外一个机械池看不到了,这里列出异常信息和排查: Disk(s): sdm, sdj, sdh, sdf, sdi, sda are formatted with Data Integrity Feature (DIF) which is unsupported. 可以看到有6块硬盘提示都不在支持,因为格式化了DIF的功能,查看 /dev/ 目录,磁盘都是存在的,但是通过 fdisk 查看就显示不了这些磁盘 查看原来的机械池状态,使用 zpool import ,这个命令在需要导入池的时候可以使用 可以看到6块硬盘不可用,剩下的硬盘没有足够多的副本,所以池无法正常导入,这里我们做的是raidz3,最多可以允许丢失3块硬盘,而6块硬盘早已超过了上限 DIF 的原因 一般DIF有两种原因,一种是扇区是520字节或者其他,不是标准的,另一种是这些型号的硬盘启用了T10保护,我们可以通过两种方式的命令确认,后面接需要检测的硬盘即可 root@freenas[~]# sg_readcap -l /dev/sdX Read Capacity results: Protection: prot_en=1, p_type=1, p_i_exponent=0 [type 2 protection] Logical block provisioning: lbpme=0, lbprz=0 Last LBA=3907029167 (0xe8e088af), Number of logical blocks=3907029168 Logical block length=512 bytes Logical blocks per physical block exponent=0 Lowest aligned LBA=0 Hence: Device size: 2000398934016 bytes, 1907729.1 MiB, 2000.40 GB, 2.00 TB root@freenas[~]# smartctl -i /dev/sda smartctl 7.3 2022-02-28 r5338 [x86_64-linux-6.1.55-production+truenas] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Vendor: IBM-XIV Product: HUS723020ALS64A4 Revision: JYK5 Compliance: SPC-4 User Capacity: 2,000,398,934,016 bytes [2.00 TB] Logical block size: 512 bytes Formatted with type 2 protection 8 bytes of protection information per logical block Rotation Rate: 7200 rpm Form Factor: 3.5 inches Logical Unit id: 0x5000cca01cbb427c Serial number: YGK9ZKTK Device type: disk Transport protocol: SAS (SPL-4) Local Time is: Sat Dec 9 16:32:48 2023 CST SMART support is: Available - device has SMART capability. SMART support is: Enabled Temperature Warning: Enabled 以上都可以看到是 type 2 protection 的保护 DIF 的解决 现代普通消费级硬盘很少有DIF功能了,而 truenas core 是支持这种硬盘的,scale 目前不支持,所以 core 升级到 scale 后就无法使用 通过查询资料,解决办法就是重新格式化。但已经升级了,如果贸然直接格式化,那这些盘不在池中,scale也无法读取数据,大概率应该没法自动恢复的。所以最终的结论就是需要还原到原系统?通过原系统格式化,然后替换硬盘恢复池数据。 安装回原系统,导入配置后还可以正常识别到池,文件读取也正常。现在通过以下命令来格式化硬盘了。先离线,每次格式化的个数取决于池的类型,比如我目前raidz3,那么一次不能超过3块,2块是比较保险的。在重新格式化后再次通过上面的命令查询是否有T10保护,确定移除保护之后替换原来离线的磁盘 # 格式化掉 T10 保护 sg_format --format --fmtpinfo=0 /dev/sd* 这个格式化的时间比正常格式化慢很多,大约用了3个小时 后续 在经过6块硬盘的折腾,发现一个事情,同时恢复多块硬盘的速度刚开始还可以,但是后续的速度会掉到 100-200M/S,而且重要的是他不会三快盘同时完成,而是有先后顺序。后续的盘又会计算需要恢复的容量,再跑一遍,也就是说多块盘共享了速度,然后又需要恢复多次。这样看起来非常浪费时间和效率,所以在后面3快盘的时候,都是格式化一块恢复一块,而速度基本上保持在300M-400M,比多块盘快多了。 我们可以使用 zpool status dev1(池名称) 来查看相关池的恢复状态、进度等 这张图剩余3小时50分钟,或者40.8%都是预估的,只有等到 issued 的大小与 scanned 大小相等的时候,才算重建完成
-