搜索到
5
篇与
的结果
-
 nginx代理dns的问题 环境背景 目前是由nginx 4层代理的 bind 服务提供 dns 解析服务,但是出现了一些问题,这里作为一个记录 配置和问题 这是原本的配置,测试dns解析基本上没有问题 upstream dns { server 192.168.10.120:53; server 192.168.10.121:53; server 192.168.10.122:53; } server { listen 53; listen 53 udp; proxy_connect_timeout 2s; proxy_timeout 2s; proxy_next_upstream on; proxy_pass dns; error_log /usr/local/nginx/logs/dns.log info; } 但日志一直有问题,要等到会话超时,也就是 proxy_timeout 之后才会正常打印日志,这样后续就会很难配合 bind 服务排查问题,时间是对不上的,而且bind服务只能记录 nginx 机器的 ip 地址 经过检索,增加了如下配置,主要是参数 proxy_responses server { listen 53; listen 53 udp; proxy_connect_timeout 2s; proxy_responses 1; proxy_timeout 2s; proxy_next_upstream on; proxy_pass dns; error_log /usr/local/nginx/logs/dns.log info; } 这个参数 nginx 官方的解释如下: Sets the number of datagrams expected from the proxied server in response to a client datagram if the UDP protocol is used. The number serves as a hint for session termination. By default, the number of datagrams is not limited. If zero value is specified, no response is expected. However, if a response is received and the session is still not finished, the response will be handled. 主要设置一个接收响应的报文,如果设置 1 ,则只要有一个数据包响应,则认为会话结束,然后它就会记录日志,这样确实解决了及时记录日志的问题 新的问题 在配置使用几天后发现了新的问题,明显感觉这几天上网、登录服务器等操作经常变慢,监控甚至又开始出现了一个很早之前的报错---域名解析失败,怀疑是上次修改的dns代理配置问题 在nginx服务器上检查了日志,可以看到如下内容: 2024/07/22 11:00:02 [error] 17500#0: *705 upstream timed out (110: Connection timed out) while proxying connection, udp client: 192.168.7.21, server: 0.0.0.0:53, upstream: "192.168.10.120:53 ", bytes from/to client:86/43, bytes from/to upstream:43/86 2024/07/22 11:00:04 [error] 17500#0: *1173 upstream timed out (110: Connection timed out) while proxying connection, udp client: 192.168.3.103, server: 0.0.0.0:53, upstream: "192.168.10.122: 53", bytes from/to client:100/176, bytes from/to upstream:176/100 2024/07/22 11:00:08 [error] 17500#0: *1313 upstream timed out (110: Connection timed out) while proxying connection, udp client: 172.23.126.234, server: 0.0.0.0:53, upstream: "192.168.10.121 :53", bytes from/to client:76/232, bytes from/to upstream:232/76 2024/07/22 11:00:08 [error] 17500#0: *38157 no live upstreams while connecting to upstream, udp client: 172.23.127.238, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:37/0, bytes from/to upstream:0/0 2024/07/22 11:00:08 [error] 17500#0: *38158 no live upstreams while connecting to upstream, udp client: 192.168.3.103, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:29/0, bytes f rom/to upstream:0/0 2024/07/22 11:00:08 [error] 17500#0: *38159 no live upstreams while connecting to upstream, udp client: 172.23.126.242, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:41/0, bytes from/to upstream:0/0 2024/07/22 11:00:08 [error] 17500#0: *38160 no live upstreams while connecting to upstream, udp client: 172.23.126.254, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:33/0, bytes from/to upstream:0/0 2024/07/22 11:00:09 [error] 17500#0: *38161 no live upstreams while connecting to upstream, udp client: 192.168.3.100, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:40/0, bytes f rom/to upstream:0/0 显然在上次增加了 proxy_responses 1 参数后,经常访问不到后端服务器,连接后端超时,等到全部 upstream 都被判定超时则提示 no live upstream,基本上符合问题现象 接下来反复打开关闭这个参数验证多次,确实发现只要开启参数,过一会儿就会有一大片的 upstream 超时日志 虽然找到了问题,但目前还未找到原因和解决办法 --- 这个参数会导致 upstream 超时,所以只能暂时关闭了 dns真实ip问题 udp的代理是不支持 proxy_protocol 的,所以无法传递真实的 ip 给 upstream,但是了解到可以使用 proxy_responses 0 配合 DSR 来实现传递真实的 ip,后续如果要这样先把 dns 服务器独立出来吧,暂时先这样,参考文档: https://www.nginx-cn.net/blog/ip-transparency-direct-server-return-nginx-plus-transparent-proxy/
nginx代理dns的问题 环境背景 目前是由nginx 4层代理的 bind 服务提供 dns 解析服务,但是出现了一些问题,这里作为一个记录 配置和问题 这是原本的配置,测试dns解析基本上没有问题 upstream dns { server 192.168.10.120:53; server 192.168.10.121:53; server 192.168.10.122:53; } server { listen 53; listen 53 udp; proxy_connect_timeout 2s; proxy_timeout 2s; proxy_next_upstream on; proxy_pass dns; error_log /usr/local/nginx/logs/dns.log info; } 但日志一直有问题,要等到会话超时,也就是 proxy_timeout 之后才会正常打印日志,这样后续就会很难配合 bind 服务排查问题,时间是对不上的,而且bind服务只能记录 nginx 机器的 ip 地址 经过检索,增加了如下配置,主要是参数 proxy_responses server { listen 53; listen 53 udp; proxy_connect_timeout 2s; proxy_responses 1; proxy_timeout 2s; proxy_next_upstream on; proxy_pass dns; error_log /usr/local/nginx/logs/dns.log info; } 这个参数 nginx 官方的解释如下: Sets the number of datagrams expected from the proxied server in response to a client datagram if the UDP protocol is used. The number serves as a hint for session termination. By default, the number of datagrams is not limited. If zero value is specified, no response is expected. However, if a response is received and the session is still not finished, the response will be handled. 主要设置一个接收响应的报文,如果设置 1 ,则只要有一个数据包响应,则认为会话结束,然后它就会记录日志,这样确实解决了及时记录日志的问题 新的问题 在配置使用几天后发现了新的问题,明显感觉这几天上网、登录服务器等操作经常变慢,监控甚至又开始出现了一个很早之前的报错---域名解析失败,怀疑是上次修改的dns代理配置问题 在nginx服务器上检查了日志,可以看到如下内容: 2024/07/22 11:00:02 [error] 17500#0: *705 upstream timed out (110: Connection timed out) while proxying connection, udp client: 192.168.7.21, server: 0.0.0.0:53, upstream: "192.168.10.120:53 ", bytes from/to client:86/43, bytes from/to upstream:43/86 2024/07/22 11:00:04 [error] 17500#0: *1173 upstream timed out (110: Connection timed out) while proxying connection, udp client: 192.168.3.103, server: 0.0.0.0:53, upstream: "192.168.10.122: 53", bytes from/to client:100/176, bytes from/to upstream:176/100 2024/07/22 11:00:08 [error] 17500#0: *1313 upstream timed out (110: Connection timed out) while proxying connection, udp client: 172.23.126.234, server: 0.0.0.0:53, upstream: "192.168.10.121 :53", bytes from/to client:76/232, bytes from/to upstream:232/76 2024/07/22 11:00:08 [error] 17500#0: *38157 no live upstreams while connecting to upstream, udp client: 172.23.127.238, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:37/0, bytes from/to upstream:0/0 2024/07/22 11:00:08 [error] 17500#0: *38158 no live upstreams while connecting to upstream, udp client: 192.168.3.103, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:29/0, bytes f rom/to upstream:0/0 2024/07/22 11:00:08 [error] 17500#0: *38159 no live upstreams while connecting to upstream, udp client: 172.23.126.242, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:41/0, bytes from/to upstream:0/0 2024/07/22 11:00:08 [error] 17500#0: *38160 no live upstreams while connecting to upstream, udp client: 172.23.126.254, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:33/0, bytes from/to upstream:0/0 2024/07/22 11:00:09 [error] 17500#0: *38161 no live upstreams while connecting to upstream, udp client: 192.168.3.100, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:40/0, bytes f rom/to upstream:0/0 显然在上次增加了 proxy_responses 1 参数后,经常访问不到后端服务器,连接后端超时,等到全部 upstream 都被判定超时则提示 no live upstream,基本上符合问题现象 接下来反复打开关闭这个参数验证多次,确实发现只要开启参数,过一会儿就会有一大片的 upstream 超时日志 虽然找到了问题,但目前还未找到原因和解决办法 --- 这个参数会导致 upstream 超时,所以只能暂时关闭了 dns真实ip问题 udp的代理是不支持 proxy_protocol 的,所以无法传递真实的 ip 给 upstream,但是了解到可以使用 proxy_responses 0 配合 DSR 来实现传递真实的 ip,后续如果要这样先把 dns 服务器独立出来吧,暂时先这样,参考文档: https://www.nginx-cn.net/blog/ip-transparency-direct-server-return-nginx-plus-transparent-proxy/ -
docker网络的疑难问题之三 前提背景 20240701 继之前的docker网络的dns解析问题 疑难问题如鲠在喉,如果不能解决,始终是一个风险,这里记录下来,尽快找到办法解决 关于 dns 解析的问题,现象为:如果本机宿主机上同时配置了VIP+BIND容器,这也是我们需要的模式,并且本机/etc/resolv.conf配置了VIP作为nameserver,那么其他容器则无法解析外网地址,容器内默认的/etc/resolv.conf配置为127.0.0.11。其他机器容器可以正常解析。这个情况在之前的帖子已经追踪过,经过排查后发现可能是NAT有问题,所以BIND服务不能使用与其他容器相同的overlay网络,而是改成host模式,当然目前来看,为了保证必定不出问题,最好是把bind服务隔离到单独的一台机器上,这样就完全避免了本机的nat转换错误问题 关于容器内访问 nginx 错误问题 从其他容器访问nginx,发现必定出现两次拒绝,一次可以访问。发现正好对应了 nginx 有三个副本,便使用 curl -v 查看了访问的ip地址,都是一样的。 [root@253258ad95d3 /]# curl http://nginx curl: (7) Failed connect to nginx:80; 拒绝连接 [root@253258ad95d3 /]# curl http://nginx curl: (7) Failed connect to nginx:80; 拒绝连接 [root@253258ad95d3 /]# curl http://nginx <html> <head><title>301 Moved Permanently</title></head> <body> <center><h1>301 Moved Permanently</h1></center> <hr><center>nginx</center> </body> </html> 查询三个 nginx 容器的ip地址,可以看到其实容器内部访问过程中还是有负载均衡的,如果是多个副本,并不会直接访问到某一个节点上,而是访问到了另外一个ip 172.21.1.185 # 其他容器curl http://nginx 解析的ip 172.21.0.200 # 节点一ip 172.21.11.227 # 节点二ip 172.21.23.214 # 节点三ip 第一个IP是容器内dns解析到的VIP(docker swarm VIP策略),另外三个则是 nginx 服务器的 3 副本实际ip 可以猜测是到了overlay网络的负载均衡地址,而overlay网络的VIP模式负载均衡是用ipvs实现的。那么如何证明呢? 我们可以进入 /var/run/docker/netns 目录下,这里包括了本机的容器、网络配置的命名空间。其中有几个特殊的是网络的,可以看到其中有一个是 lb_1jo63pzkt,这个前缀 lb + 后面的 id 刚好是我们需要的overlay id,所以基本上确定是这个 使用命令进入 nsenter --net=lb_1jo63pzkt sh 接着可以使用命令查询防火墙规则和ipvs规则,需要注意的是,这里的命令是调用的宿主机操作系统命令,所以宿主机需要提前安装ipvs,yum -y install ipvsadm 查看防火墙mangle规则: iptables -L -t mangle -n MARK all -- 0.0.0.0/0 172.21.1.185 MARK set 0x11e 第一行是 nginx 的VIP规则,其中最后的MARK打标值为 0x11e,转换为10进制为286 接着查看 ipvs 规则: ipvsadm -l FWM 286 rr -> 172.21.0.200:0 Masq 1 0 0 -> 172.21.11.227:0 Masq 1 0 0 -> 172.21.23.214:0 Masq 1 0 0 根据MARK值286可以找到对应的三个转发条目。那么172.21.1.185是怎么回事呢?如何解释呢? 既然打标和转发都有了,可以确定172.21.1.185 ip应该是在本机的,否则怎么转发呢? 所以通过 ifconfig命令查看,发现此ip在接口上,同时可以看到此接口还有非常多的额外ip,应该都是其他容器的VIP地址,附加到这里做ipvs转发 最终方案 选择解藕服务,前面增加4层nginx,高可用放到此处,VIP也不再放到docker集群中,docker集群只需要保证自身的集群高可用即可,docker中再运行7层nginx,接受4层的请求。至此VIP所在机器上的容器无法解析dns的问题解决 20240702 nginx启动 docker service create --name nginx \ --mount type=bind,src=/docker/others/nginx/conf,dst=/usr/local/nginx/conf \ --mount type=bind,src=/docker/others/nginx/conf.d,dst=/usr/local/nginx/conf.d \ --mount type=bind,src=/docker/others/nginx/logs,dst=/usr/local/nginx/logs \ --network mynets \ -p target=80,published=80 \ -p target=443,published=443 \ -p target=8080,published=8080 \ --constraint node.role==manager \ --replicas 1 \ harbor.succez.com/sz/nginx-v20220701v1
-
-
-
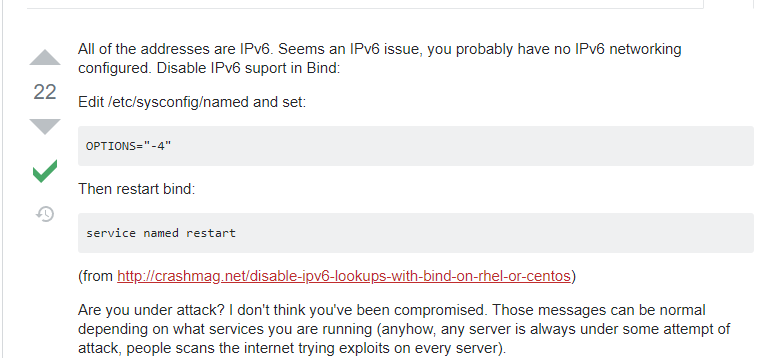
bind无法解析DNS的问题 现象 公司内部dns地址,服务为bind,版本9.8.2 当服务器设置此dns时候,有些域名无法解析。如: ping api.qichacha.com 经过排查,发现有意思的是,正常使用下无法解析包括ping,但使用dig可以解析出地址。 原因 通过dig发现,解析出来返回内容很多,和其他可以解析域名唯一的区别 解决 开启tcp,因为较早的原因貌似dns使用udp解析时对报文大小有限制,当同时也开启了tcp的时候,通过抓包发现,ping此域名先是udp后续转为了tcp。但是有其他办法能够解决此问题吗。为什么dig没有问题呢? https://www.citrix.com/blogs/2012/08/29/when-udp-is-not-enough-what-to-do-with-large-dns-responses/ https://serverfault.com/questions/1041615/how-to-enable-dns-over-tcp-for-resolving-names-on-linux https://www.google.com/search?q=bind+server+truncated+retrying+in+tcp+mod&ei=0gBdYrfqMYOZr7wPwbqg-AI&ved=0ahUKEwi3m8Pu-Zz3AhWDzIsBHUEdCC8Q4dUDCA4&uact=5&oq=bind+server+truncated+retrying+in+tcp+mod&gs_lcp=Cgdnd3Mtd2l6EAMyBwghEAoQoAFKBAhBGAFKBAhGGABQrwNYtBFgtxNoBHAAeACAAX2IAZcEkgEDMS40mAEAoAEBwAEB&sclient=gws-wiz is#4ADb48F*z4&V