搜索到
289
篇与
的结果
-
 docker通过宿主机PID获取容器 场景 某docker的宿主机很卡,显示负载很高,可能是由某个容器导致的,但是通过宿主机的top看资源使用没有明显的异常,不能很好区分,其他的异常表现为显示有zombie进程,那么现在查出进程号后如何知道宿主机的此进程号对应的哪个容器呢? 解决 其实对于正常情况来说查进程号是能够看到容器不少信息的,如果没有大量重复容器的情况下基本上能够通过这些信息定位到相关的容器。但是我们遇到的情况是: 第一有大量重复的容器,正常情况查询宿主机进程显示的内容都是一样的 第二此进程已经zombie,显示的内容为僵尸进程内容,所以需要使用以下命令来查询此进程号对应的容器: docker inspect -f '{{.State.Pid}} {{.Id}}' $(docker ps -q) | grep <Pid>
docker通过宿主机PID获取容器 场景 某docker的宿主机很卡,显示负载很高,可能是由某个容器导致的,但是通过宿主机的top看资源使用没有明显的异常,不能很好区分,其他的异常表现为显示有zombie进程,那么现在查出进程号后如何知道宿主机的此进程号对应的哪个容器呢? 解决 其实对于正常情况来说查进程号是能够看到容器不少信息的,如果没有大量重复容器的情况下基本上能够通过这些信息定位到相关的容器。但是我们遇到的情况是: 第一有大量重复的容器,正常情况查询宿主机进程显示的内容都是一样的 第二此进程已经zombie,显示的内容为僵尸进程内容,所以需要使用以下命令来查询此进程号对应的容器: docker inspect -f '{{.State.Pid}} {{.Id}}' $(docker ps -q) | grep <Pid> -
-
jenkins api触发构建 0x0 背景 基于文档jenkins构建docker镜像的问题,现在有了进一步的需求,在构建镜像的时候需要定制oem版本的包,或者后续可能会有多个版本,那么每个版本都新增一个jenkins任务维护起来太过于麻烦,所以需要有办法能提供一个通用的打包任务 0x1 问题 要能够通用的打包任务,重点在于以下: 打包的时候来提交参数,war的地址/war的版本来定制,其他的代码文件与之前的固定版本一致即可 基于上面这个问题,要么jenkins任务的时候弹窗给出参数,要么使用接口来触发任务了 0x2 解决 以上第一个问题是没有问题的,当前固定版本的构建也是通过脚本获取了war文件和war版本信息,后续的操作跟文件无关了,所以这部分代码通用。第二个问题选择使用jenkins api的方式触发构建 0x3 jenkins api jenkins api需要token鉴权,所以使用一个普通用户创建一个token即可(保证安全),登录jenkins后点击用户名,再选择configure,最后选择show Legacy API Token,即可复制出有效token,之后再按照jenkins api文档给出的示例调用方式,这里还有一个重点问题,因为需要提供参数,所以接口要选择'/buildWithParameters',但使用下面调用请求返回报错: curl -XPOST http://jenkins.xxx.com/job/镜像-common/buildWithParameters --user yuctest:xxxxx4a25f85629a846ba7285d7xxxxx --data war=ftp://192.168.xx.xx/xxx/xxx/123.war --data version=cccccc 前端的报错内容很模糊,无参考价值,但jenkins后台日志提示如下: java.lang.IllegalStateException: This build is not parameterized! 基本上可以推断出我们使用的传参接口,但是创建的任务却没有启用相关的功能,所以应该要修改以下任务。 在任务配置的通用栏下,可以看到选项'This project is parameterized',勾选后还要继续设置传送哪种参数,否则是无法保存的,我们这里需要传送两个参数,并且都是字符串,所以选择了string类型,并且设置名称,值可以不设置,之后变可以在后面的执行步骤中获取这两个变量了 0x4 最后 使用接口测试就没有问题了,余下的步骤也参考之前的固定版本就行 20220609 在jenkins中点击构建的时候会弹到参数页面,输入给定的参数就行了,不是一定需要通过api调用
-
jenkins打包出现的域名解析问题 0x1 某分支打包失败,通过日志查看到如下错误: stack: Error: getaddrinfo ENOTFOUND cdn.npmmirror.com at GetAddrInfoReqWrap.onlookup [as oncomplete] (node:dns:71:26) [npminstall:get] retry GET https://registry.npmmirror.com/caniuse-lite/-/caniuse-lite-1.0.30001349.tgz after 100ms, retry left 4, error: Error: getaddrinfo ENOTFOUND cdn.npmmirror.com at GetAddrInfoReqWrap.onlookup [as oncomplete] (node:dns:71:26) { errno: -3008, code: 'ENOTFOUND', syscall: 'getaddrinfo', hostname: 'cdn.npmmirror.com', name: 'RequestError', data: undefined, path: '/packages/caniuse-lite/1.0.30001349/caniuse-lite-1.0.30001349.tgz', status: -1, headers: {}, res: [Object] }, status: -1, headers: {}, 错误是挺明显的,地址无法解析到,并且是下载nodejs模块的过程中。接着在服务器上测试了下,确实无法访问: # 使用ping [root@localhost product-docs]# ping cdn.npmmirror.com ping: cdn.npmmirror.com: 未知的名称或服务 # 使用nslookup > server 192.168.10.184 Default server: 192.168.10.184 Address: 192.168.10.184#53 > cdn.npmmirror.com ;; Truncated, retrying in TCP mode. ;; Connection to 192.168.10.184#53(192.168.10.184) for cdn.npmmirror.com failed: connection refused. 但这里有个疑问,应该一直是使用的淘宝源,这个地址倒是第一次见到,于是粘贴到浏览器访问,确实是访问到了新地址上,那么可以确定源是没有问题的,依旧是淘宝,是地址访问的问题。 0x2 继续查看nslookup报错的信息,可以看到尝试使用tcp模式,但接下来访问tcp端口出现异常,可以继续排查dns问题了。进入dns服务器查询端口情况,发现确实没有监听,重启解决 0x3 此问题与这个问题一致: https://yuc.pub/uncategorized/295/ 0x4 之前是重启过dns服务的,但没有监听tcp就比较异常,而且重启过程中也没有报错,如何解决呢?
-
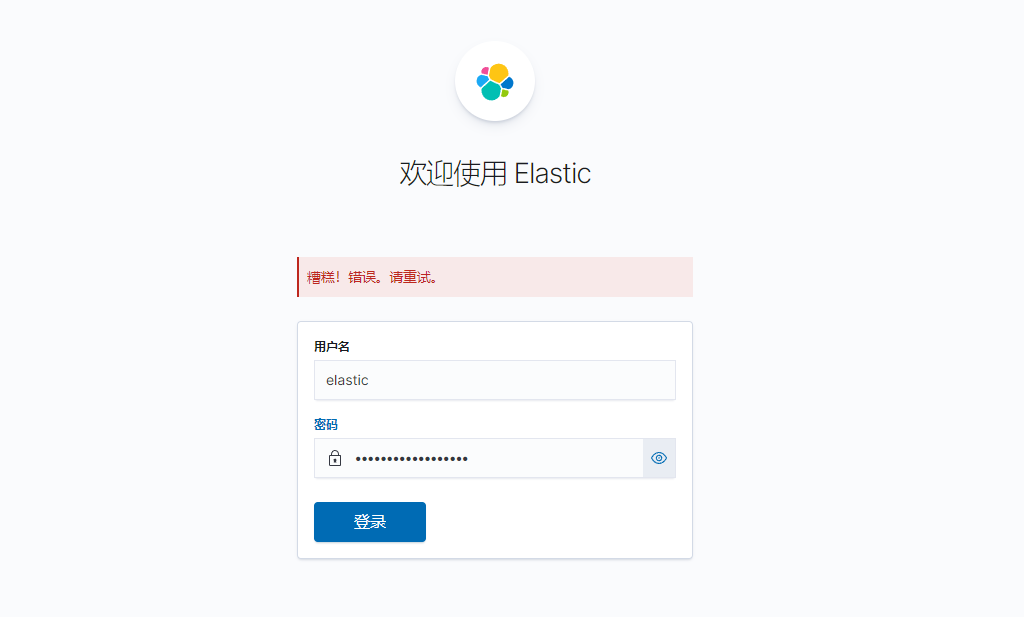
elasticsearch磁盘空间的问题 问题现象 selenium定时截图kibana,但是发现数据连续几天都是一样的,感觉好久没有更新了一样,怀疑是查询有问题,尝试登录kibana手动执行查询,但有如下报错: 排查经过 排查了kibana,logstash日志中有报错,但都没有明显的相关内容,那只能继续排查elasticsearch日志,在日志文件logcheck.log中发现了明显的异常: [2022-05-30T14:20:24,401][WARN ][o.e.c.r.a.DiskThresholdMonitor] [lognode1] high disk watermark [90%] exceeded on [1__xs753R3uOME1Sugp4kg][lognode1][/data/elfk/els/data/nodes/0] free: 181gb[5.1%], shards will be relocated away from this node; currently relocating away shards totalling [0] bytes; the node is expected to continue to exceed the high disk watermark when these relocations are complete 可以看到告警提示高水位线90%,于是我们查询服务器磁盘空间,确实目录使用率已经超过了90%了。清理空间后解决。 感悟 这个问题一开始的提示太模糊了,以致于我们排查了整个elfk日志才能定位,而且如果我们只是排查服务器性能,那么90%+的空间使用率也算正常,无法直接显示出问题在哪里,最后要么对elasticsearch特性很熟悉,要么对els故障排查熟悉,否则还是需要耗费一定时间的。 最后我们看看els关于空间的说明: https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cluster.html#disk-based-shard-allocation