搜索到
289
篇与
的结果
-
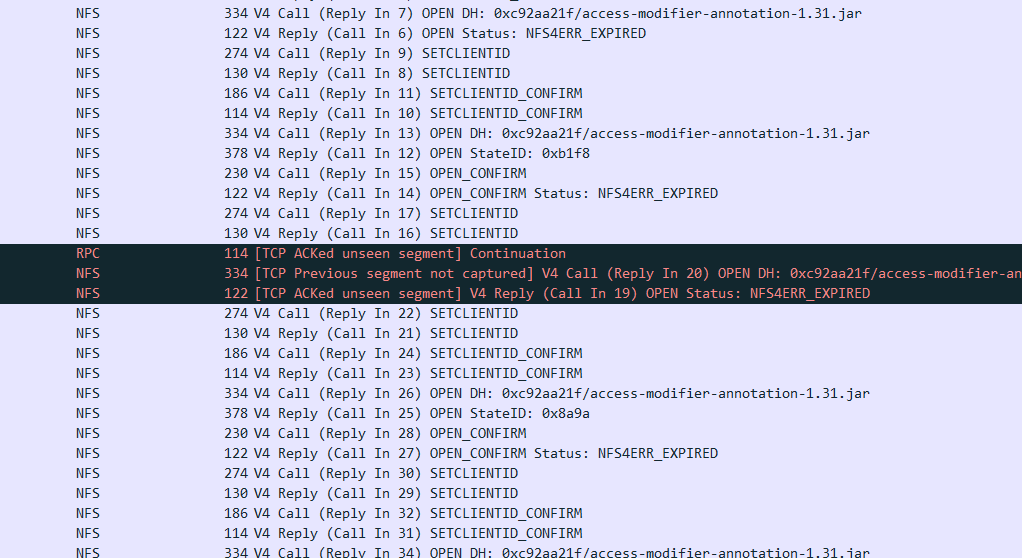
 nfs优化与错误Lock reclaim failed、Input/output error 0x0 异常 挂载目录卡住,查看 /var/log/messages 有如下错误: NFS: nfs4_reclaim_open_state: Lock reclaim failed 0x1 参数优化 先说说系统参数优化: _netdev,vers=4.0,rw,noatime,nodiratime,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,proto=tcp 基本上挂载的时候跟直接使用这些参数即可,其中 vers=4.0 需要显示的写出来,centos7测试使用 vers=4 或者不写的情况下,使用 mount 可以观察得到版本为 4.1 ,所以为了使用 4.0 版本,一定要显示写 4.0 0x2 服务优化 如果并发较大的情况下,可以增大 nfs 的进程数,以提高并发 0x3 系统优化 linux对nfs客户端同时请求数进行了限制,可以用下面的命令查询,大部分机器默认是2,是比较小的。可以通过以下命令查询当前的数值: cat /proc/sys/sunrpc/tcp_slot_table_entries 内核编译的默认最大是2,可以增大设置成128,需要重新挂载nfs echo "options sunrpc tcp_slot_table_entries=128" >> /etc/modprobe.d/sunrpc.conf echo "options sunrpc tcp_max_slot_table_entries=128" >> /etc/modprobe.d/sunrpc.conf sysctl -w sunrpc.tcp_slot_table_entries=128 优化后重启机器,或者重新挂载nfs PS. 服务器 fstab 或者命令挂载实例: /etc/fstab 192.168.xx.xx:/aaa/bbb /opt/bbb nfs _netdev,vers=4.0,rw,noatime,nodiratime,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,proto=tcp 0 0 mount mount -t nfs -o _netdev,vers=4.0,rw,noatime,nodiratime,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,proto=tcp 192.168.xx.xx:/mnt/dev1/aaa /tmp/aaa 2023.12.07 补充更新 上面的内核参数以及挂载方法只是当时临时解决了问题,但是后来在其他机器上无法解决。所以并不是一个最终方案。试过了nfs3、nfs4.0、nfs4.1版本,更换过机器多种版本内核,仍然无法解决,可以参考抓包内容: 在挂载4.0版本的时候,ls文件卡住,包内容如下: 可以看到双方有非常多的设置 clientid、确认 的操作,这显然是不正常的 在挂载4.1版本的时候,ls文件很快,创建文件、读取文件、vi文件错误,但是创建目录可以 抓包内容(仅对vi做抓包、后续观察more是同样的问题): 可以看到有非常多的 NFS4ERR_EXPIRED 这明显也是不正常的,因为不管是链接还是会话,都不可能这么快过期,在一个 vi 或者 more 的时间过期多次 关于此错误代码的解释 13.1.5.3. NFS4ERR_EXPIRED (Error Code 10011) A stateid or clientid designates locking state of any type that has been revoked or released due to cancellation of the client's lease, either immediately upon lease expiration, or following a later request for a conflicting lock. 在后续的查阅资料中也基本没有相关的案例、或者没有解决办法。于是猜测是 openbds 的 nfs BUG 之类。但是业务太多,其他几个挂载点目前没问题,不好重启 nfs 服务。 基于我们场景的现状,小文件非常多,有大量web项目war包解压出来的,还有jenkins打包的代码文件,所以目前的想法是采用多个 nfs 服务来提供这些不同服务的挂载。首先是避免大量读写小文件到一个 nfs 中处理不过来,再就是出现问题的时候,其中某个nfs重启也不影响其他的。
nfs优化与错误Lock reclaim failed、Input/output error 0x0 异常 挂载目录卡住,查看 /var/log/messages 有如下错误: NFS: nfs4_reclaim_open_state: Lock reclaim failed 0x1 参数优化 先说说系统参数优化: _netdev,vers=4.0,rw,noatime,nodiratime,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,proto=tcp 基本上挂载的时候跟直接使用这些参数即可,其中 vers=4.0 需要显示的写出来,centos7测试使用 vers=4 或者不写的情况下,使用 mount 可以观察得到版本为 4.1 ,所以为了使用 4.0 版本,一定要显示写 4.0 0x2 服务优化 如果并发较大的情况下,可以增大 nfs 的进程数,以提高并发 0x3 系统优化 linux对nfs客户端同时请求数进行了限制,可以用下面的命令查询,大部分机器默认是2,是比较小的。可以通过以下命令查询当前的数值: cat /proc/sys/sunrpc/tcp_slot_table_entries 内核编译的默认最大是2,可以增大设置成128,需要重新挂载nfs echo "options sunrpc tcp_slot_table_entries=128" >> /etc/modprobe.d/sunrpc.conf echo "options sunrpc tcp_max_slot_table_entries=128" >> /etc/modprobe.d/sunrpc.conf sysctl -w sunrpc.tcp_slot_table_entries=128 优化后重启机器,或者重新挂载nfs PS. 服务器 fstab 或者命令挂载实例: /etc/fstab 192.168.xx.xx:/aaa/bbb /opt/bbb nfs _netdev,vers=4.0,rw,noatime,nodiratime,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,proto=tcp 0 0 mount mount -t nfs -o _netdev,vers=4.0,rw,noatime,nodiratime,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,proto=tcp 192.168.xx.xx:/mnt/dev1/aaa /tmp/aaa 2023.12.07 补充更新 上面的内核参数以及挂载方法只是当时临时解决了问题,但是后来在其他机器上无法解决。所以并不是一个最终方案。试过了nfs3、nfs4.0、nfs4.1版本,更换过机器多种版本内核,仍然无法解决,可以参考抓包内容: 在挂载4.0版本的时候,ls文件卡住,包内容如下: 可以看到双方有非常多的设置 clientid、确认 的操作,这显然是不正常的 在挂载4.1版本的时候,ls文件很快,创建文件、读取文件、vi文件错误,但是创建目录可以 抓包内容(仅对vi做抓包、后续观察more是同样的问题): 可以看到有非常多的 NFS4ERR_EXPIRED 这明显也是不正常的,因为不管是链接还是会话,都不可能这么快过期,在一个 vi 或者 more 的时间过期多次 关于此错误代码的解释 13.1.5.3. NFS4ERR_EXPIRED (Error Code 10011) A stateid or clientid designates locking state of any type that has been revoked or released due to cancellation of the client's lease, either immediately upon lease expiration, or following a later request for a conflicting lock. 在后续的查阅资料中也基本没有相关的案例、或者没有解决办法。于是猜测是 openbds 的 nfs BUG 之类。但是业务太多,其他几个挂载点目前没问题,不好重启 nfs 服务。 基于我们场景的现状,小文件非常多,有大量web项目war包解压出来的,还有jenkins打包的代码文件,所以目前的想法是采用多个 nfs 服务来提供这些不同服务的挂载。首先是避免大量读写小文件到一个 nfs 中处理不过来,再就是出现问题的时候,其中某个nfs重启也不影响其他的。 -
truenas更换损坏、故障的存储池硬盘 0x1 参考文档: https://www.truenas.com/docs/core/coretutorials/storage/disks/diskreplace/ 磁盘、存储池故障的日志参考: 现象1 New alerts: * Device /dev/gptid/e1fd123b-8795-11ed-bee4-b083fedec519 is causing slow I/O on pool dev1. 现象2 New alerts: * Pool dev1 state is ONLINE: One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected. 现象3 New alert: * Pool dev1 state is DEGRADED: One or more devices are faulted in response to persistent errors. Sufficient replicas exist for the pool to continue functioning in a degraded state. The following devices are not healthy: * Disk IBM-XIV HUS723020ALS64A4 YFHEUB3G is FAULTED * Device: /dev/da6, failed to read SMART values. * Device: /dev/da6, Read SMART Self-Test Log Failed. 在现象1中提示io缓慢的时候如何定位是哪个磁盘呢?先可以通过命令查看每个盘的情况 root@freenas[/dev/gptid]# zpool status pool: boot-pool state: ONLINE scan: scrub repaired 0B in 00:24:37 with 0 errors on Sat Jul 29 04:09:37 2023 config: NAME STATE READ WRITE CKSUM boot-pool ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 da13p2 ONLINE 0 0 0 da12p2 ONLINE 0 0 0 errors: No known data errors pool: dev1 state: DEGRADED status: One or more devices are faulted in response to persistent errors. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Replace the faulted device, or use 'zpool clear' to mark the device repaired. scan: scrub repaired 0B in 11:48:41 with 0 errors on Sun Jul 30 11:48:42 2023 config: NAME STATE READ WRITE CKSUM dev1 DEGRADED 0 0 0 raidz3-0 DEGRADED 0 0 0 gptid/15954610-bc06-11ed-a407-b083fedec519 ONLINE 0 0 0 gptid/e1b6b74b-8795-11ed-bee4-b083fedec519 ONLINE 0 0 0 gptid/e1fd123b-8795-11ed-bee4-b083fedec519 FAULTED 12 11 0 too many errors gptid/bb486a3d-c7d5-11ed-a407-b083fedec519 ONLINE 0 0 0 gptid/e249a2c9-8795-11ed-bee4-b083fedec519 ONLINE 0 0 0 gptid/034b850b-bc17-11ed-a407-b083fedec519 ONLINE 0 0 0 gptid/e1e4d7ce-8795-11ed-bee4-b083fedec519 ONLINE 0 0 0 gptid/e23f6124-8795-11ed-bee4-b083fedec519 ONLINE 0 0 0 gptid/e2971a19-8795-11ed-bee4-b083fedec519 ONLINE 0 0 0 gptid/e25d107c-8795-11ed-bee4-b083fedec519 ONLINE 0 0 0 errors: No known data errors 可以使用如下命令查看 gptid 对应的分区: label status | tail -n +2 | sort -k53 接着会看到有的盘会有多个分区,那么每个分区分别是什么呢,可以使用如下命令查询: gpart show
-
zabbix主动模式和被动模式配置 0x0 配置区别 被动模式 agent 配置参考如下: LogFile=/tmp/zabbix_agentd.log Server=192.168.3.xxx ServerActive=192.168.3.xxx Hostname=192.168.10.xxx Timeout=30 配置比较简单,其中 ServerActive 应该是可以不用设置的,再就是 Timeout 参数官方推荐是不能太大的,因为被动模式下,所有数据由服务端获取,而拉取数据的线程是有限的,那么超时时间太大可能会影响所有机器的数据获取,但是如果设置太小,可能会出现自定义脚本运行时间太长,而服务端已经等待超时 被动模式 web 配置参考如下: 在 web 上选择添加机器,接口部分填入正确的 agent ip和端口,之后选择模板即可 主动模式 agent 配置参考如下: LogFile=/tmp/zabbix_agentd.log StartAgents=0 Server=xxx ServerActive=xxx:10055 Hostname=xxx Timeout=30 主动模式设置 StartAgents 为 0 ,表示关闭被动模式,然后设置 ServerActive 的ip或者主机名,如果服务端端口不是默认的10051,那么需要带上端口号 主动模式 web 配置参考如下: 在 web 上添加机器,接口部分可以随意填,主机名一定要跟 agent 中配置文件对应,再就是模板选择带 active 的
-
portainer之使用 0x1 首先说说为什么使用 portainer,因为他在免费开源的同类管理容器平台的工具中,算是比较好用的。再就是我们技术人员可以操控命令行为什么还需要它呢?答案是给其他人员用,并且使用起来也相对方便。比如我们想要进入 docker swarm 集群中的某个容器内,那么需要先定位到此服务在哪个机器,然后在此机器中进入,但是使用 portainer 在列表中找到后可以直接进入。 0x2 再说说具体的使用感受,一开始使用的社区版,主要功能是有的,什么镜像管理,容器管理,创建服务,服务管理。但是体验差的地方也有,比如:1. 权限管理简单,要么只读要么管理员。 2. 不稳定,经常出现刷新不出数据的情况 针对上面的情况,我选择了申请试用商业版,但惊喜的是商业版 license 可以免费试用 5 个 agent 节点。果然商业版不一样,上面的问题都得到了解决。最后看看 portainer 的部署步骤: agent 部署: docker service create \ --name portainer_agent \ --network mynets \ -p 9001:9001/tcp \ --mode global \ --constraint 'node.platform.os == linux' \ --mount type=bind,src=//var/run/docker.sock,dst=/var/run/docker.sock \ --mount type=bind,src=//var/lib/docker/volumes,dst=/var/lib/docker/volumes \ portainer/agent:2.18.3 server 部署: docker service create \ --name portainer \ --network mynets \ --mount type=bind,src=/docker/others/portainer/data,dst=/data \ --publish 9000:9000 \ --constraint 'node.role == manager' \ --replicas=1 \ harbor.succez.com/base/portainer/portainer \ -H "tcp://tasks.portainer_agent:9001" --tlsskipverify
-
github之访问和认证失败 0x1 先说说墙内如何在github提交或者拉取,首先我们需要一个http/https协议的代理服务,我这边是使用的 privoxy 接着我们配置 git 的代理: git config --global http.proxy http://127.0.0.1:8118 git config --global https.proxy http://127.0.0.1:8118 参考文档: https://gist.github.com/evantoli/f8c23a37eb3558ab8765 按照文档所说,是支持针对某个地址来配置代理的,格式如下: git config --global http.https://domain.com.proxy http://proxyUsername:proxyPassword@proxy.server.com:port git config --global http.https://domain.com.sslVerify false 不过这里我并没有折腾这种方案 在全局配置了 git 代理后,拉取和推送github.com终于算是有弹出内容了(无代理会因为网络问题一直卡住无回显) 0x2 解决了网络问题,又出来了新的问题,在输入了登录邮箱和密码后,回显认证失败: authentication failed 我非常奇怪,并且再三通过网页登录确定了账号密码没有错误,后来又怀疑是仓库权限的问题 在一直无法解决之后经过了一波查阅资料,发现是github不提供账号密码验证方式了,而是使用 token 的方式,所以我们需要创建一个 token 来作为密码验证,步骤如下: Settings / Developer Settings / Tokens(classic) 在网页上操作简单明了,就是权限上为了安全不需要给太多,就选择 repo 即可 拿到了此 token 之后,我们再次在本地执行push到github,在密码处输入此 token 成功了。经过尝试,发现账号处不管输入用户名或者邮箱都是可以的。