搜索到
289
篇与
的结果
-
 impala的调优以及导数 优化问题 交换内存调优 vm.swappiness = 0 内存大小 内存最少128G,256G更佳,内存的大小直接影响了查询和导入数据,在cdh5.5版本后取消了内存溢出写入磁盘,查询或者倒数时内存溢出会立即错误 硬盘空间 硬盘一定要足够,在正式环境中,我们需要使用默认设置复制快为3,那么存储空间需求为三倍 hdfs块大小、列存储 hdfs调整数据块大小,在使用parquet列式存储时候,大块文件对性能提升非常大,反之小文件会增加hdfs寻块的时间,推荐的块大小为1G 合适的字段分区 字段分区能够极大提升查询性能,但也需要遵从一定限制,过多的分区有可能会导致数据分布不均,某些块可能非常小,导致查询时间变长 导入数据的压缩格式 压缩能够减少存储空间的使用,但是牺牲了cpu的性能,不论是在查询,还是在导入的时候,都需要把数据进行解压,会消耗更多的cpu时间,对于cpu密集型的工作负载,可以关闭压缩功能,同时,官方测试不使用压缩比压缩查询稍快,使用snappy性能优于gzip压缩 集群负载类型和网络 cdh又分为网络工作负载,cpu工作负载,内存工作负载等类型,所以不仅仅内存需要满足一定需求。磁盘IO,网络带宽(内网10G/s)也都需要满足需求 raid类型 磁盘不需要使用raid,因为hdfs本来就是使用大量廉价机器来提升性能,但raid1明显违背了这一点,raid0数据不可靠,当一个节点宕机,此节点所有的磁盘数据丢失,如果真的需要使用raid来提升性能,那么使用raid5+0,raid1+0,官方推荐方式是jbod,这种方式性能比raid0差不太多,但是可靠性更高,当一块盘损坏时,hdfs会自动重建该盘的数据到其他磁盘,我们只需要替换该盘即可。且官方提到raid0受制于最慢的那块盘,如果最慢的磁盘数据没有写入,其他磁盘无论多块也是不完整的数据,特别是raid0在使用时间过长后损坏的几率以及变慢的几率变高 查看表的信息统计 show table stats TABLE_NAME 查看表的分区 show partitions TABLE_NAME 对表进行信息统计 compute stats TABLE_NAME 关闭压缩 set compression_codec=none; 缓存表 hdfs cacheadmin -addPool 'impala_pool' -owner impala -limit 40000000000 alter table TABLE_NAME set cached in 'impala_pool' with replication=3 alter table TABLE_NAME set uncached 数据导入问题 字段支持类型 impala支持的字段类型有区别于mysql或者oracle等关系型数据库,其中NUMBER改为DECIMAL,VARCHAR2改为VARCHAR,DATE改为TIMESTAMP 数值类型的精度问题 如果在导入数据的时候提示 Error converting column: 34 to DECIMAL(10,0),则表明数据类型不对,可以查看oracle数据库的对应字段的数值精度,再修改即可 数据导入流程和分隔符 先根据原表创建表结构,然后导出数据,这里选择好分隔符field=\"0x1c\" record=\"0x1e\",再根据导出数据时的分隔符创建impala普通表,然后创建parquet表,把普通表导入parquet表,或者先对parquet表进行分区后再导入,最后对导入的数据使用compute stats进行优化 分隔符问题 通过修改impala导入时默认的lines terminated换行符和escape取消转义,原因可能是impala默认换行符\n也能匹配到被取消转义后的oracle换行符 oracle导入数据到impala 这个脚本是之前从oracle导出数据并且导入到impala中,最后转换为parquet表 #!/bin/bash # #列出需要导入的表名,可以是一张表,也可以是多张表 tables="F_BRLXJJB_NEW F_BASY_DBZ F_BASY_JBQK f_basy_jbqk_gx F_BASY_ZZY F_BASY_SSFL F_BASY_FY F_BASY_BFBZ F_BASY_BACX F_FJZL_NEW F_BASY_CYBR F_YBCYRS_NEW F_YBCYRS_NEW_NB" #删除历史的一些遗留文件,或者异常退出产生的遗留文件等 rm -rf /tmp/files/* hadoop fs -rm -r -f /tmp/files/* mkdir /tmp/files hadoop fs -mkdir /tmp/files chmod 777 /tmp/files #抽取oracle中的数据 for i in `echo $tables`;do su - oracle -c "sqluldr user=USER/PASS@SID query=\"select * from ${i}\" file=/tmp/files/${i}.txt field=\"0x1c\" record=\"0x1e\" serial=true charset=utf8 safe=yes" & while true;do n=`ps -ef | grep sqluldr | grep -v grep | wc -l` if [ ${n} -lt 3 ];then break else sleep 60s fi done done while true;do n=`ps -ef | grep sqluldr | grep -v grep | wc -l` if [ ${n} -eq 0 ];then break else sleep 60s fi done #把抽取的数据上传到hdfs for i in `echo $tables`;do hadoop fs -put /tmp/files/${i}.txt /tmp/files & while true;do n=`ps -ef | grep "\-put /tmp/files" | grep -v grep | wc -l` if [ ${n} -lt 3 ];then break else sleep 60s fi done done while true;do n=`ps -ef | grep "hadoop fs -put" | grep -v grep | wc -l` if [ ${n} -eq 0 ];then break else sleep 60s fi done sleep 1200s #删除原来的表,这里的库名根据实际情况修改,然后创建表 for i in `echo $tables`;do impala-shell -q "drop table if exists default.txt_${i}" impala-shell -f tables/${i} done #修改上传文件的权限 hadoop fs -chmod -R 777 /tmp/files #加载数据到普通的表中 for i in `echo $tables`;do impala-shell -q "load data inpath '/tmp/files/${i}.txt' into table default.txt_${i}" done #设置不压缩表,貌似在这里设置没有效果 impala-shell -q "set compression_codec=none" #加载数据到parquet表,上面没有删除parquet表,所以这里是加载数据的语句 for i in `echo $tables`;do impala-shell -f psql/${i} done #对parquet表进行元数据更新操作 for i in `echo $tables`;do impala-shell -q "compute stats default.${i}" done
impala的调优以及导数 优化问题 交换内存调优 vm.swappiness = 0 内存大小 内存最少128G,256G更佳,内存的大小直接影响了查询和导入数据,在cdh5.5版本后取消了内存溢出写入磁盘,查询或者倒数时内存溢出会立即错误 硬盘空间 硬盘一定要足够,在正式环境中,我们需要使用默认设置复制快为3,那么存储空间需求为三倍 hdfs块大小、列存储 hdfs调整数据块大小,在使用parquet列式存储时候,大块文件对性能提升非常大,反之小文件会增加hdfs寻块的时间,推荐的块大小为1G 合适的字段分区 字段分区能够极大提升查询性能,但也需要遵从一定限制,过多的分区有可能会导致数据分布不均,某些块可能非常小,导致查询时间变长 导入数据的压缩格式 压缩能够减少存储空间的使用,但是牺牲了cpu的性能,不论是在查询,还是在导入的时候,都需要把数据进行解压,会消耗更多的cpu时间,对于cpu密集型的工作负载,可以关闭压缩功能,同时,官方测试不使用压缩比压缩查询稍快,使用snappy性能优于gzip压缩 集群负载类型和网络 cdh又分为网络工作负载,cpu工作负载,内存工作负载等类型,所以不仅仅内存需要满足一定需求。磁盘IO,网络带宽(内网10G/s)也都需要满足需求 raid类型 磁盘不需要使用raid,因为hdfs本来就是使用大量廉价机器来提升性能,但raid1明显违背了这一点,raid0数据不可靠,当一个节点宕机,此节点所有的磁盘数据丢失,如果真的需要使用raid来提升性能,那么使用raid5+0,raid1+0,官方推荐方式是jbod,这种方式性能比raid0差不太多,但是可靠性更高,当一块盘损坏时,hdfs会自动重建该盘的数据到其他磁盘,我们只需要替换该盘即可。且官方提到raid0受制于最慢的那块盘,如果最慢的磁盘数据没有写入,其他磁盘无论多块也是不完整的数据,特别是raid0在使用时间过长后损坏的几率以及变慢的几率变高 查看表的信息统计 show table stats TABLE_NAME 查看表的分区 show partitions TABLE_NAME 对表进行信息统计 compute stats TABLE_NAME 关闭压缩 set compression_codec=none; 缓存表 hdfs cacheadmin -addPool 'impala_pool' -owner impala -limit 40000000000 alter table TABLE_NAME set cached in 'impala_pool' with replication=3 alter table TABLE_NAME set uncached 数据导入问题 字段支持类型 impala支持的字段类型有区别于mysql或者oracle等关系型数据库,其中NUMBER改为DECIMAL,VARCHAR2改为VARCHAR,DATE改为TIMESTAMP 数值类型的精度问题 如果在导入数据的时候提示 Error converting column: 34 to DECIMAL(10,0),则表明数据类型不对,可以查看oracle数据库的对应字段的数值精度,再修改即可 数据导入流程和分隔符 先根据原表创建表结构,然后导出数据,这里选择好分隔符field=\"0x1c\" record=\"0x1e\",再根据导出数据时的分隔符创建impala普通表,然后创建parquet表,把普通表导入parquet表,或者先对parquet表进行分区后再导入,最后对导入的数据使用compute stats进行优化 分隔符问题 通过修改impala导入时默认的lines terminated换行符和escape取消转义,原因可能是impala默认换行符\n也能匹配到被取消转义后的oracle换行符 oracle导入数据到impala 这个脚本是之前从oracle导出数据并且导入到impala中,最后转换为parquet表 #!/bin/bash # #列出需要导入的表名,可以是一张表,也可以是多张表 tables="F_BRLXJJB_NEW F_BASY_DBZ F_BASY_JBQK f_basy_jbqk_gx F_BASY_ZZY F_BASY_SSFL F_BASY_FY F_BASY_BFBZ F_BASY_BACX F_FJZL_NEW F_BASY_CYBR F_YBCYRS_NEW F_YBCYRS_NEW_NB" #删除历史的一些遗留文件,或者异常退出产生的遗留文件等 rm -rf /tmp/files/* hadoop fs -rm -r -f /tmp/files/* mkdir /tmp/files hadoop fs -mkdir /tmp/files chmod 777 /tmp/files #抽取oracle中的数据 for i in `echo $tables`;do su - oracle -c "sqluldr user=USER/PASS@SID query=\"select * from ${i}\" file=/tmp/files/${i}.txt field=\"0x1c\" record=\"0x1e\" serial=true charset=utf8 safe=yes" & while true;do n=`ps -ef | grep sqluldr | grep -v grep | wc -l` if [ ${n} -lt 3 ];then break else sleep 60s fi done done while true;do n=`ps -ef | grep sqluldr | grep -v grep | wc -l` if [ ${n} -eq 0 ];then break else sleep 60s fi done #把抽取的数据上传到hdfs for i in `echo $tables`;do hadoop fs -put /tmp/files/${i}.txt /tmp/files & while true;do n=`ps -ef | grep "\-put /tmp/files" | grep -v grep | wc -l` if [ ${n} -lt 3 ];then break else sleep 60s fi done done while true;do n=`ps -ef | grep "hadoop fs -put" | grep -v grep | wc -l` if [ ${n} -eq 0 ];then break else sleep 60s fi done sleep 1200s #删除原来的表,这里的库名根据实际情况修改,然后创建表 for i in `echo $tables`;do impala-shell -q "drop table if exists default.txt_${i}" impala-shell -f tables/${i} done #修改上传文件的权限 hadoop fs -chmod -R 777 /tmp/files #加载数据到普通的表中 for i in `echo $tables`;do impala-shell -q "load data inpath '/tmp/files/${i}.txt' into table default.txt_${i}" done #设置不压缩表,貌似在这里设置没有效果 impala-shell -q "set compression_codec=none" #加载数据到parquet表,上面没有删除parquet表,所以这里是加载数据的语句 for i in `echo $tables`;do impala-shell -f psql/${i} done #对parquet表进行元数据更新操作 for i in `echo $tables`;do impala-shell -q "compute stats default.${i}" done -
hadoop以及hdfs的若干问题 hdfs丢失块过多的问题 在HDFS客户端,并执行如下命令: 执行命令退出安全模式 hadoop dfsadmin -safemode leave 执行健康检查,删除损坏掉的block hdfs fsck / -delete namenode 空间不足无法使用 在导入数据的时候把namenode误作为datanode,直接从namenode上传数据到hdfs中,当namenode的磁盘完全被存满之后报错namenode is in safemode。想要删除上传的文件,发现已经无法删除,并且再次提示此错误,想通过以下命令强制离开安全模式safemode: hadoop dfsadmin -safemode leave 但再次操作删除文件仍然进入safemode,此时进入循环 最后的解决方案:重启hadoop集群,查看是否在safemode中,不是,则删除文件,成功 datanode各节点分布数据差异大 分布最小的节点20%,最大的60%,这样下次导入数据容易导致磁盘不足,需要对集群中分布的数据做balancer,在任意节点执行: hadoop balancer -threshold 5 #节点之间允许5%大小的容量差值,大小在0-100 设置hdfs中平衡数据的传输带宽 如果传输的带宽过大或者过小都有可能影响节点性能,需要根据情况取一个合适的值,参数 dfs.balance.bandwidthPerSec 默认值: 1048575(1M/s),在balancer的时候每个节点传输的最大带宽,可以修改hdfs-site.xml来修改平衡的带宽 <property> <name>dfs.balance.bandwidthPerSec</name> <value>20971520</value> <description> Specifies the maximum bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. </description> </property> 这里调整传输的最大带宽为 20M/s,当然也可以临时修改带宽: hdfs dfsadmin -setBalancerBandwidth 104857600 如果是cdh,则可以通过图形化页面修改值来持久化修改 对当前上传的文件设置冗余 hdfs中上传的文件,如果不特定修改参数,那么副本数就是之前的默认值,但如果对于一些临时大文件,不想要多个副本,则可以在上传的时候手动设置其副本数即可: hadoop fs -D dfs.replication=1 -put /file/to/path /file/to/hadooppath 如果想要修改以前已上传文件的副本数,则可以通过如下命令: hadoop fs -setrep -R cdh中root用户无法在任何hdfs文件夹中创建文件 发现使用root用户也无法在hdfs 根目录下创建文件夹,google了一下,有几个解决办法: 方法一: a. In cloudera manager, you can change the settings: hdfs->configuration->view&edit, uncheck the Check HDFS Permissions dfs.permissions and restart the hdfs. # 具体操作:在cdh的web中点击集群-hdfs-配置 方法二: b. I resolved the issue by creating a supergroup in /etc/group and updated the user logins on it. I mean user should be part of HDFS supergroup to have access to write on HDFS. # 具体操作:在服务器中添加supergroup组,然后添加root用户到这个组中/etc/group文件内容直接修改即可supergroup:x:501:root
-
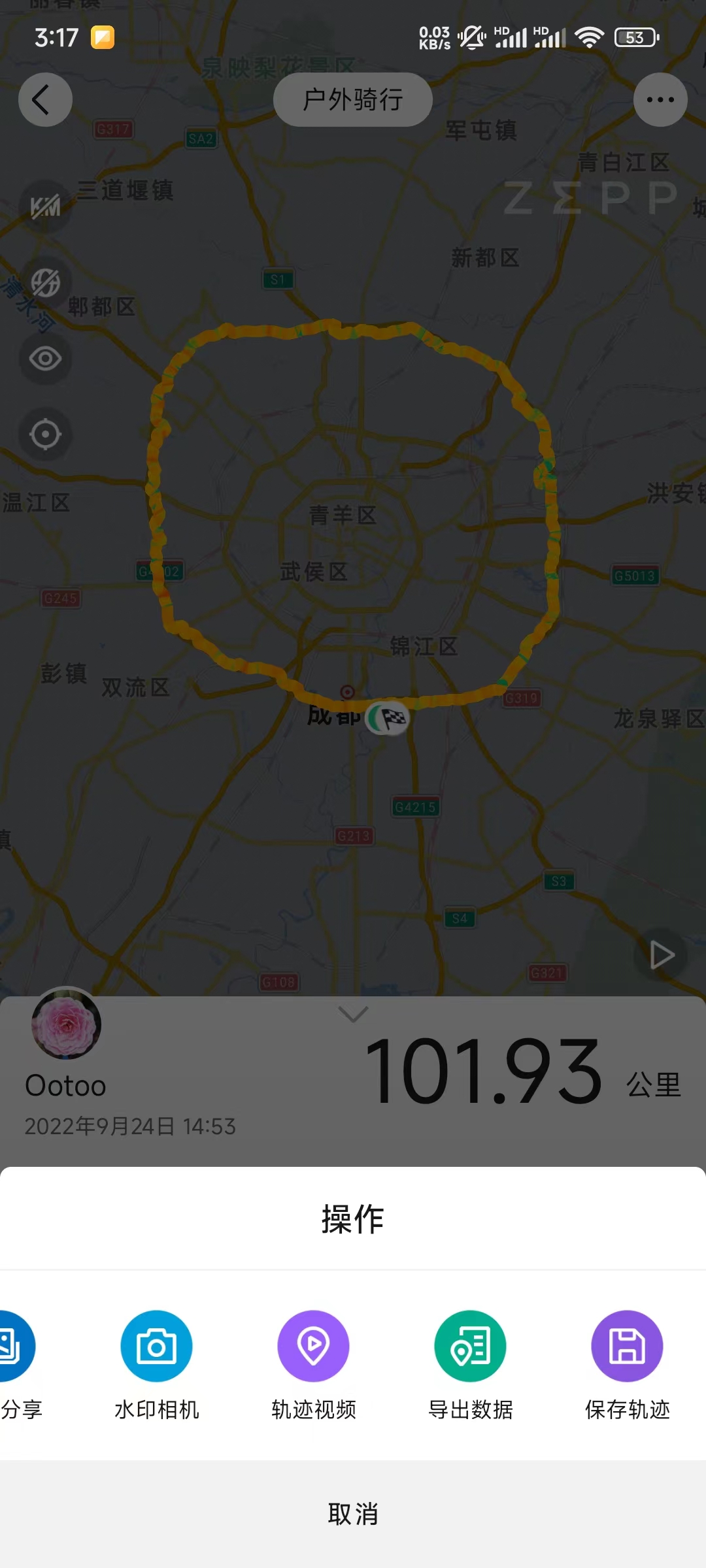
amazfit数据导出的方法 为什么要导出数据 目前使用的amazfit手表,平台是自家的 zepp,虽然专业,但是相对比较封闭,如果我们想把数据同步到其他平台,那么就需要先想办法从amazfit上导出数据 同步方案 有两个想法,一个是同步到佳明connect,一个是行者,或者二者全部同步。但是实际查询了一些网上的办法,感觉都比较麻烦,行者、佳明都不直接支持这款手表。后面到官网查看,发现二者是可以通过上传fit文件来手动上传数据的,并且佳明connect还支持更多的格式,如 tcx、gpx 等 amazfit导出 amazfit如何导出也检索了不少资料,后面经过查看app和手表,发现app内进入到某个详细运动后,右上角有自带的工具可以导出,并且格式还支持不少,这里我们导出 fit 即可,如下图 其他平台导入 接下来我们就可以进去到 行者 或者 garmin connect 后台导入记录了 不过手动导出导入还是很麻烦,希望官方能够支持各平台对接,或者看看能否通过第三方的方式来绕一下实现自动同步 20240423 导入到行者、佳明、顽鹿 fit文件是可以直接导入到行者的,但是码表要选择佳明,虽然不是佳明的码表,主要数据没问题 导入佳明就不过多介绍了 导入顽鹿,在网页登录顽鹿后,点击自行车 -> OTM -> 我的活动 点击上传记录即可 但目前不管是行者还是顽鹿,只有总时长而运动时长是0,而佳明没有区分,只有运动时长是显示正常,不知道是平台问题还是 amazfit 导出的 fit 文件问题 硬件设备 后续看是弄一个码表,还是以上平台都比较支持的手表吧
-
-
linux迁移根分区 0x1 根分区迁移的背景 有时候系统根分区初始分配太小,后期使用过程中根分区很容易满,并且当初也没有使用 lvm,无法通过 lvm 来扩展分区大小,所以需要另外研究方法来更改根分区大小 0x2 修改根分区大小方法 分配一块新磁盘 sdb 并且分区 sdb1 创建 pv、vg、lvm,根分区修改为 lvm 有利于以后扩展 pvcreate /dev/sdb1 vgcreate vg_root /dev/sdb1 lvcreate -L 4G -n lv0 vg_root mkfs.ext4 /dev/vg_root/lv0 创建挂载目录,挂载到新 lvm,复制现在的根分区文件到新分区 mkdir /mnt/root/ mount /dev/vg_root/lv0 /mnt/root/ rsync -avxHAX --numeric-ids --progress / /mnt/root/ mount --bind /dev/ /mnt/root/dev/ chroot /mnt/root/ mount -t proc /proc /proc mount -t sysfs /sys /sys vgscan vgchange -ay 根据新的 root 结构 (lvm信息)生成新的内核启动文件 mkinitrd -v /boot/initrd-`uname -r`.lvm.img `uname -r` umount /sys umount /proc exit 把新的启动文件移动到原系统boot目录中 mv /mnt/root/boot/initrd-`uname -r`.lvm.img /boot 把系统原旧启动文件备份,新启动文件重命名为旧文件,这样后续可以直接重启,不需要修改启动项 cd /boot mv initramfs-3.10.0-xxx.el7.x86_64.img initramfs-3.10.0-xxx.el7.x86_64.img.bak mv initrd-`uname -r`.lvm.img initramfs-3.10.0-xxx.el7.x86_64.img 修改根分区的挂载点 查询新磁盘 blkid a. 修改 /etc/fstab 中根分区为新的 UUID b. 同上UUID,修改 /boot/grub2/grub.cfg 中 root=UUID= 部分的内容(有多处) 以上操作没问题,可以重启了,重启后新盘会作为根分区,但是boot仍然是旧的(当前的场景是 boot 也有单独的分区) 把旧boot目录内容拷贝出来,然后卸载,再把备份内容复制到boot目录下,接下来在 /etc/fstab 中拿掉 boot 挂载内容,再次重启,即可验证拿掉boot分区挂载 至此原磁盘全部空闲 在虚拟机控制台,在此虚拟机不关机状态下删除原磁盘 重建引导。当前虽然使用的新盘启动,但仍然识别为 sdb,上面把原盘删除了,所以要把引导安装到新盘sdb上 grub2-install /dev/sdb grub2-mkconfig -o /boot/grub2/grub.cfg 重启。再次进入系统可以看到变成了 sda,所以再次更新一下 grub.cfg grub2-mkconfig -o /boot/grub2/grub.cfg 到此时,看起来基本上没有问题了,但其实还有一个坑,如果给这台机器添加一块磁盘,那么就会发现机器无法启动了,把盘移除则恢复正常,猜测原理如下: 在上面删除原磁盘后,虚拟机本身的记录磁盘顺序没有改变,更换系统的新盘仍然是靠后,如果再加一块盘,那么这个最新的盘会填补删除盘的位置。此时我们启动系统,引导会告诉系统在第一块盘,但第一块是最新的空盘,导致启动失败 要解决这个问题,那么需要修改虚拟机配置的磁盘id序号,操作如下 a. 关机 b. 在虚拟机配置中,找到这块唯一的系统盘,修改id顺序为最小 c. 重启,测试正常 d. 关机,添加新硬盘 e. 启动,至此迁移全部完成 0x3 efi 的处理方式 上面的扩展根分区方式是传统的bios启动。那如果是 uefi 的启动方式呢? Linux 会有一个隐藏的 分区,那么该如何迁移此分区到新盘上?